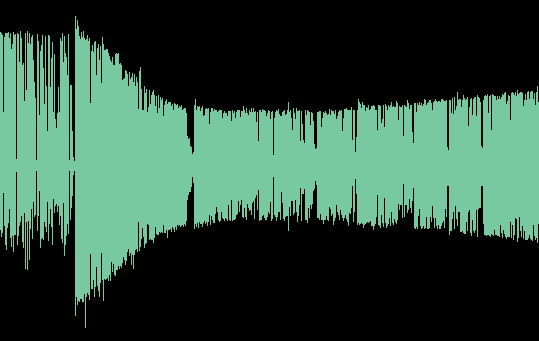
Mir liegt inzwischen auch der Montag vor der Umstellung auf R128 vor. Zum großen Vergleichshören bin ich noch nicht gekommen, allerdings sind die zeitweise auffallenden "Kratzigkeiten" auch dort bereits drin, z.B. in den Nachrichten zu hören und bei O-Tönen. Im angehängten "Montag"-Beispiel gibt es eine solche Störung z.B. schon im ersten Wort der Nachrichten ("die") und dann beim Korrespondenten ("Ehepaare", "die über ihre").
Die Summenkompression scheint "fetter" gewesen zu sein vor der Umstellung, am Dienstag klingt das Sprechermikrofon etwas schlanker als am Montag. Dafür gab es am Montag das Pumpen nicht, das dann am Dienstag sowohl bei Sprache als auch bei den Soundelementen so störend auffiel. Die Regelung am Dienstag (und bis heute, so nichts verändert worden ist) ist hektisch und sprunghaft - das ist das, was stört. Ich habe mal - unterstellend, daß die Soundelemente mit Festpegel ausgespielt werden - die 7-Uhr-Nachrichtenopener von Montag und Dienstag voneinander subtrahiert. Wären sie exakt identisch gepegelt und identisch prozessiert, käme da leidlich genau Stille heraus. Es ist sehr interessant, was real herauskommt. Beispiel im Anhang. Was "schaltet" da so sprunghaft am Pegel herum?
Wenn ich R128 richtig verstanden habe, geht es um homogene Lautheit über die einzelnen Programmelemente, nicht um die brachiale Anpassung jedes Momentes an eine einheitliche Lautheit. Dynamik und kurzzeitige Lautheitsunterschiede (kürzer als die R128-Zeitkonstante) sind also zu erhalten. Wenn dramaturgisch erwünscht (Hörspiel! Klassik!), sind auch längere Passagen mit niedrigerer Lautheit selbstverständlich zu erhalten. Es darf nicht auffällig herumgeregelt werden an in sich anständig (ästhetisch) produzierten Elementen. Genau da wird aber offenbar bei SWR Info in Echtzeit eingegriffen - sage ich als ebenfalls Laie.
@radneuerfinder
Die Sprache/Musik-Kennung (im UKW-RDS ebenso vorhanden wie im seligen DSR-Satellitenradio und im heutigen DVB-System sowie meines Wissens nach auch in DAB) ist recht ungeeignet, ein "flüssig" gefahrenes Programm mit Ramptalk u.ä. zu kontrollieren. Das gäbe dauernd fiese Sprünge, wenn die Lautstärken für M (Mikrofon aus) und S (Mikrofon an) unterschiedlich eingestellt wären. Sowas funktionierte nur bei z.B. ernsthaften Klassiksendungen, in denen es nur entweder oder gibt. Das ist kaum praxistauglich.
Das "korrekte" Pegeln von Sprache und Musik zueinander ist hochgradig schwierig bis unmöglich, wenn man die perfekte Universaleinstellung sucht. Was daheim (evtl. sogar unter Kopfhörer) als "homogen" empfunden wird, verliert spätestens bei 130 km/h im Mittelklassewagen die Sprachverständlichkeit, während sich die Musik meist noch gut genug durchsetzt (die Wahrheit dürfte wohl sein, daß die Verständlichkeit da auch leidet, aber bei der Musik gar keine Textverständlichkeit erwartet wird und es deshalb nicht auffällt, während man bei der Moderation dann schon in den Apparat kriechen will).
Auch kann man z.B. bei Rock/Pop heutiger Machart kaum mit völlig unkomprimiertem Mikrofonweg dagegenhalten - man bekäme wegen der hochgradig unterschiedlichen Lautheit einer unbearbeiteten "schlanken" Stimme gegenüber heutiger U-Musik-Produktionen ein abstruses Spitzenpegelverhältnis - ich schätze (!) daß man manchen Sprecher in den Spitzen um 12 dB und mehr über die "Spitzen" der U-Musik pegeln müßte. Damit verliert man über weite Strecken des Programms Lautheit. Etwas Peak Limiting und dezentes "Anfetten" des Mikrofonweges ist also durchaus sinnvoll und sorgt für angenehmeres Hören - das Musik-Umfeld bei Popwellen ist ja weitaus dynamikärmer als eine menschliche Stimme. Da geht es aber immer noch nicht um Brachialkompression, die jeglichen Hintergrund aus dem "Studio" (das heute meist ob seiner Raumakustik diesen Namen nicht verdient) brutal nach vorne holt. Man kann das dezenter machen und vor allem ohne hörbare Regeleffekte und ohne Verzerrungen.
Allerdings sind gerade die "Dudelwellen" ideale R128-Umgebungen: die Musik liegt ohnehin komplett im System, man kann sie dort also gleich nach R128 ausgepegelt reinstellen, die Audioelemente ebenfalls. Dann ist Ausspielen auf "Regler-Null" automatisch fast immer passend. Ein leicht angefettetes Mikrofon ist dann auch wesentlich leichter dazu homogen zu bekommen. Um andere Wege (Telefon, ...) muß man sich freilich auch kümmern. Es sollte aber wesentlich leichter sein als bei einem Programm "alter" Prägung, wo Redakteure CDs oder gar Schallplatten mitbringen (alte Sendefahrer erkannten am Rillenspiegel der Platte, wie laut sie in etwa sein wird) und Gesprächsrunden mit zig Studiogästen zu pegeln sind.
@CosmicKaizer
Ich bin auch Laie - habe nie in der Hörfunktechnik gearbeitet. Die Ausspielwege und ihre Besonderheiten hast Du schon erkannt, und damit auch das Problem. Nimm Dir mal den DLF vor und strapaziere ihn z.B. im Auto. Ist er anständig anhörbar? Falls Du das für Dich mit "ja" beantwortest, dann rufe Dir mal ins Gedächtnis, daß der DLF sehr dezent bearbeitet ist (was nicht verhindern kann, daß manche zugelieferten Sendungen dann doch wie Tonne klingen).
Ich behaupte: ein Großteil dessen, was wir heute im Radio an "Sound" hören, dient gar nicht der besseren Hörbarkeit in akustisch problematischen Situationen, sondern dem "Corporate Sound" des Programms. Es soll einen Wiedererkennungseffekt erzeugen. Siehe z.B. MDR Thüringen: rotzigst verzerrter, wummernder Sound, der dazu führt, daß mein schwerhöriger 80-jähriger Vater kein Wort versteht. Inzwischen läuft also der nur sehr dezent bearbeitete DLF auf dem von Haus aus voluminös klingenden
DDR-Küchenradio - auch wenn da keine Meldungen aus Thüringen kommen. Das Processing von MDR Thüringen dient also gar nicht einer Erhöhung der Sprachverständlichkeit, sondern dem ganzen Gegenteil.
Solches Processing ist technisch nicht begründet. Von einer ARD-Anstalt kenne ich die Story, daß die Wellenleitung dann mit dem Sounddesigner und der Technik "Hörsitzungen" veranstaltet, bei der ein UKW-Summenprozessor vorhanden ist und off air verändert werden kann. Und dann fordern die Programmleute halt "mehr Bass" oder "grellere Höhen" oder "fetteren Sound" und die Technik hat die Aufgabe, das unter Wahrung der UKW-Parameter zu realisieren. Übrigens ist sowas auch ein Grund dafür, warum ich nicht bei einer heutigen Rundfunkanstalt arbeiten wollen würde. Das ist in etwa das gleiche, als würde ein Verkehrsbetrieb-Management das Werkstattpersonal dazu nötigen, Busse vor die Wand der Reparaturhalle zu fahren, bis die Frontscheibe splittert.
Im Falle von SWR Info geht es definitiv nicht um diese Art Processing, sondern um den Versuch, eine homogene Lautheit zu erzeugen - allerdings betrachte ich zumindest das, was vor einer Woche zu hören war, als "Versuch gescheitert" - siehe oben. Da regelt etwas nervig schnell. Ich bezweifele, daß es hier um Geschmackssachen geht. Die betreffen die absichtliche (Effekt)bearbeitung des Signals, nicht so etwas wie bei SWR Info.
So etwas muß natürlich nachjustiert werden. Und es dürfte auch dem SWR aufgefallen sein, daß da was nicht paßt. Da ist das alte Klangbild deutlich stabiler als dieses Gezitter.
Etwas anderes ist die Frage nach "Kleingeräte / Mobilempfang vs. Stereoanlage": fürs erste wäre da mein Vorschlag, den DVB-Weg vom UKW-Weg abzukoppeln und ohne das UKW-Processing anzubieten. Der DVB-Weg wird stationär gehört (eben via Sat, Kabel digital oder auch Kabel UKW, so von DVB in der Kopfstation umgesetzt wird), man kann da von deutlich weniger gestörter Hörumgebung ausgehen. Dennoch wäre durchaus zu diskutieren, ob man DVB vielleicht doch nicht komplett "ohne" anbietet, sondern durch ein dezentes UKW-Processing laufen läßt, wie es z.B. die Kulturwellen verwenden. Also Tiefpaß bei 16 kHz und Peak-Limiting mit Emphasisberücksichtigung. Ein Processing, wie es z.B. BR Klassik auf UKW anbietet, wäre eine Wohltat für alle Pop-Wellen. Das komplette puristische "unbearbeitet durchlassen" wäre da gar nicht nötig und ist klanglich davon nur im Direktvergleich zu unterscheiden. Man hätte damit auch die Sicherheit, daß bei Umsetzungen DVB -> Kabel-UKW keine Spuckeffekte bei Hubüberschreitung auftreten können. Und man könnte das DVB-Signal so immer noch als Havarie-Backupzuführung zu UKW-Standorten einsetzen, ohne die UKW-Parameter zu verletzen. Es klänge dann für die Zeit des Ausfalls der Regelzuführung nur deutlich anders als sonst. Wieviele Minuten im Jahr träfe dies zu?
Etwas anderes ist es, wenn Hörfunkwellen den DVB-"Endkundenweg" als Regelzuführung nutzen. Meines Wissens nach tut dies der MDR mit etlichen Frequenzen von MDR Info und MDR Sputnik. Da ist natürlich der UKW-Sound auf DVB anzubieten, ansonsten bräuchte man an jedem UKW-Standort ein separates Processing, was derbe ins Geld geht. Ein Ausweg wäre hier, solange Kapazität vorhanden ist, einen entsprechend bearbeiteten separaten 192er MP2-Stream als UKW-Feed mit über DVB zu verbreiten. Dies ist kaum praktikabel, denn freie Kapazität ist auf dem Hörfunktransponder zwar bissl drauf, wird aber auch als Overhead für die Vormultiplexbildung gebraucht. Und meines Wissens nach muß jede Anstalt ihren Datenmengen-Anteil zahlen.
Deshalb wäre es sehr wünschenswert, auch auf UKW vom entstellenden Schweineprocessing abzukommen, aber da glaube ich eher an den Sieg des Kommunismus als an eine entsprechende Entwicklung.