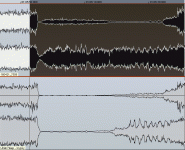
Radiowaves
Gesperrter Benutzer
Ich hätte das präzisieren müssen. Es handelt sich um eine einstige technische Führungskraft, die mit den Vorgängen bestens vertraut sein müßte. Techniker tun sowas (Klangzerstörung) meiner Erfahrung nach nie freiwillig, ältere, jahrzehntelang im Produktionsbereich arbeitende Techniker erst recht nicht. Die Reaktion kam nicht nur für mich absolut überraschend (nahezu schockierend), sondern auch für die Technik-Koryphäe, die mir mit dem Kommentar "ein Kämpfer für den guten Ton" die Emailadresse des Mannes gab.
Ich gehe inzwischen davon aus: dieser Mann ist (Von wem? Intendanz? Hörfunkdirektion?) regelrecht gebrochen worden und hat dann, um sich selbst weiteres Leid zu ersparen, einfach schwarz gegen weiß und gut gegen schlecht ausgetauscht. Zu deutsch: er vertritt aus Gründen des Selbstschutzes halt nun das Gegenteil von dem, was sein Techniker-Ethos, sein musikalisches und kulturelles Verständnis und sein ästhetisches Verständnis sagen. Gesundes und würdiges Leben ist das nicht. Und zu wünschen ist es auch niemandem, sein Lebenswerk selbst zerstören und danach die Zerstörung rechtfertigen zu müssen.
Letztlich paßt das aber zu dem, was ich aus anderen ARD-Anstalten teils zu hören bekomme. Da spricht ein einstmals leidenschaftlicher Hörfunktechniker, dem der Wechsel von ganz woandersher zum ARD-Hörfunk vor vielen Jahren richtig gutgetan hatte, heute in Verachtung von den Programmen und ist seit langem krank und nicht mehr arbeitsmäßig belastbar. Da freut sich ein ARD-Urgestein auf seinen Vorruhestand, weil er dann endlich das durch Wellenchefs und Hörfunkdirektoren verursachte Leid los wird. Da werden Techniker von den Programmchfs gezwungen, den schlechtmöglichsten "Sound" einzustellen (so kaputt wie möglich) und müssen, um das vorgegebene Ziel zu erreichen, sogar einen neuen Klangverbieger kaufen, weils der vorhandene nicht so pervers kann wie gewünscht.
Das ganze System ist hochgradig kaputt und pervers. Wir diskutieren das ja meist ausgiebig inhaltlich, aber die technische Seite ist genauso betroffen.
Und ich bin froh, nicht beim Hörfunk zu arbeiten. Hätte ich früher gerne mal. Aber so doch nicht.
Ich gehe inzwischen davon aus: dieser Mann ist (Von wem? Intendanz? Hörfunkdirektion?) regelrecht gebrochen worden und hat dann, um sich selbst weiteres Leid zu ersparen, einfach schwarz gegen weiß und gut gegen schlecht ausgetauscht. Zu deutsch: er vertritt aus Gründen des Selbstschutzes halt nun das Gegenteil von dem, was sein Techniker-Ethos, sein musikalisches und kulturelles Verständnis und sein ästhetisches Verständnis sagen. Gesundes und würdiges Leben ist das nicht. Und zu wünschen ist es auch niemandem, sein Lebenswerk selbst zerstören und danach die Zerstörung rechtfertigen zu müssen.
Letztlich paßt das aber zu dem, was ich aus anderen ARD-Anstalten teils zu hören bekomme. Da spricht ein einstmals leidenschaftlicher Hörfunktechniker, dem der Wechsel von ganz woandersher zum ARD-Hörfunk vor vielen Jahren richtig gutgetan hatte, heute in Verachtung von den Programmen und ist seit langem krank und nicht mehr arbeitsmäßig belastbar. Da freut sich ein ARD-Urgestein auf seinen Vorruhestand, weil er dann endlich das durch Wellenchefs und Hörfunkdirektoren verursachte Leid los wird. Da werden Techniker von den Programmchfs gezwungen, den schlechtmöglichsten "Sound" einzustellen (so kaputt wie möglich) und müssen, um das vorgegebene Ziel zu erreichen, sogar einen neuen Klangverbieger kaufen, weils der vorhandene nicht so pervers kann wie gewünscht.
Das ganze System ist hochgradig kaputt und pervers. Wir diskutieren das ja meist ausgiebig inhaltlich, aber die technische Seite ist genauso betroffen.
Und ich bin froh, nicht beim Hörfunk zu arbeiten. Hätte ich früher gerne mal. Aber so doch nicht.
")